
Which AI Bots Are Really Crawling Websites in 2026? Real Data From 1.4 Million Tracked Events
Published by The Laughing Professor
The Difference Between Assumptions and Reality
There is no shortage of articles discussing AI bots, AI crawlers, search engines, indexing systems, and machine learning models.
Most of those articles are based on:
- Industry reports
- Surveys
- Third-party datasets
- Speculation
- Vendor marketing
This article is different.
The statistics below come from a single website using my own Traffic Intelligence platform, collecting both server-side and JavaScript-confirmed visitor data over 277 days.
The website being analysed is:
This is not client data.
This is not aggregated data.
This is not purchased data.
This is real traffic collected from one independent website.
Current Traffic Dataset
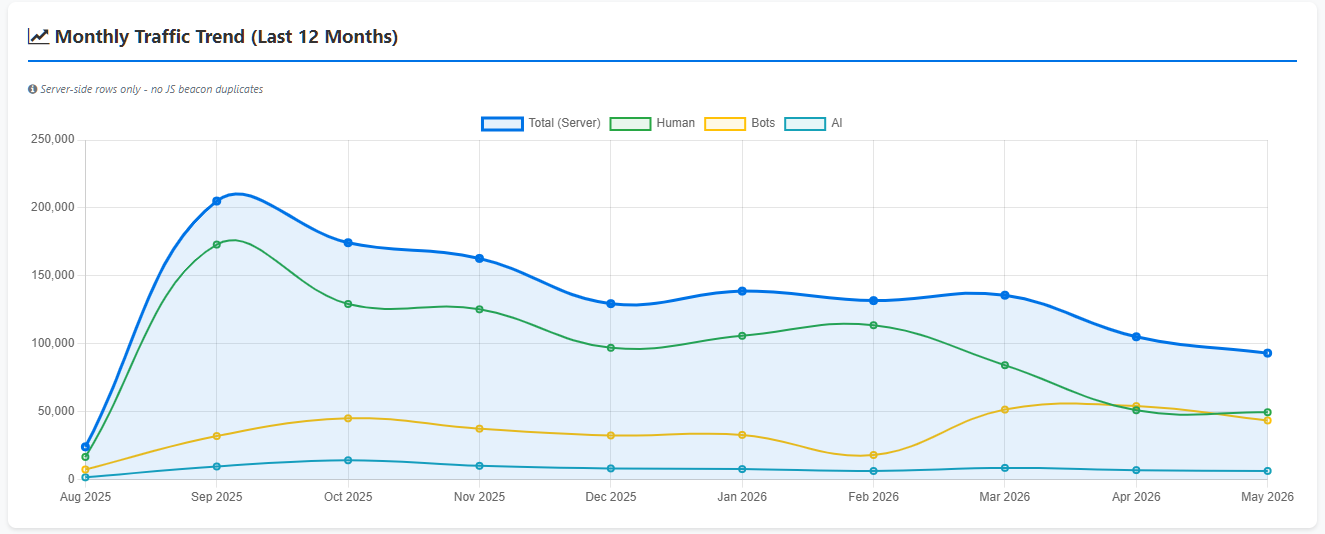
Over the tracking period, the website recorded:
Metric | Total |
|---|---|
Total Tracked Events | 1,423,640 |
Server Requests | 1,299,330 |
Unique IP Addresses | 117,263 |
Confirmed Human Page Views | 27,441 |
Bot Requests | 354,416 |
AI Requests | 79,845 |
Successful Requests (200) | 976,630 |
4XX Errors | 12,268 |
5XX Errors | 2,560 |
Days Active | 277 |
The Most Important Statistic
Many website owners still assume:
Traffic = Visitors
The data tells a very different story.
Over 1.4 million tracked events were recorded, yet only 27,441 page views were confirmed through JavaScript beacon tracking.
This demonstrates something most analytics dashboards hide:
Not every request represents a human visitor.
A large percentage of website activity comes from:
- Search engines
- AI crawlers
- Monitoring systems
- Scrapers
- Automated scanners
- Security probes
- Bots
Understanding the difference matters.
Which AI Crawlers Are Visiting?
The following AI-related crawlers were identified through server-side tracking.
AI Traffic Breakdown
AI Crawler | Requests | Unique IPs |
|---|---|---|
Amazonbot | 1,503 | 414 |
ChatGPT | 234 | 155 |
Meta AI | 223 | 137 |
ClaudeBot | 210 | 31 |
Timpibot | 89 | 1 |
CommonCrawl | 85 | 3 |
OpenAI | 42 | 10 |
PerplexityBot | 22 | 7 |
Bytespider | 5 | 3 |
YouBot | 5 | 2 |
GPTBot | 5 | 1 |
Perplexity | 3 | 3 |
MistralBot | 1 | 1 |
Google-Extended | 1 | 1 |
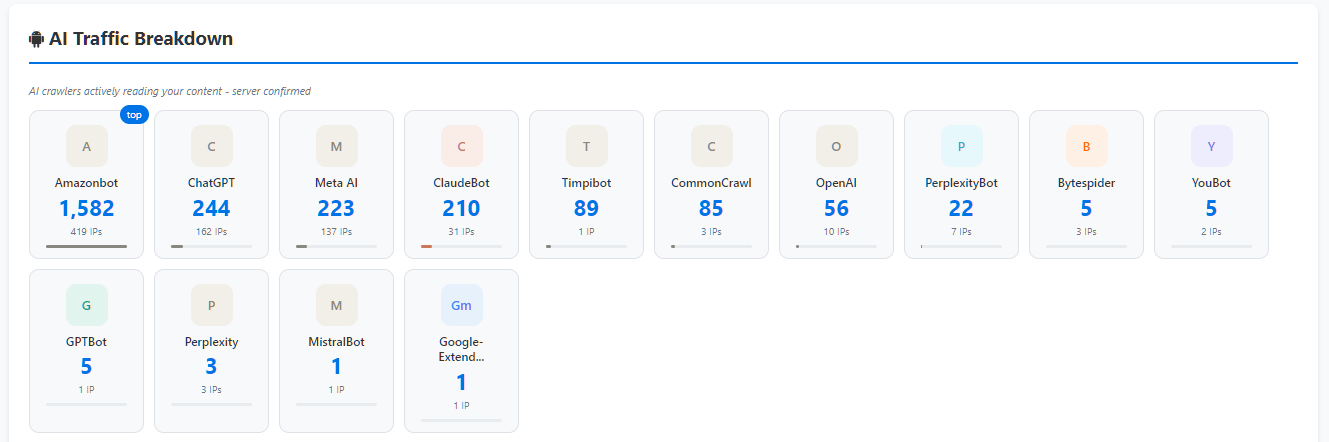
The Biggest Surprise
Many people assume OpenAI-related crawlers dominate the web.
Based on the data collected from this website, that was not the case.
Amazonbot generated significantly more requests than any other identified AI crawler.
This does not necessarily mean Amazon is using more content than other providers.
It simply means that on this website, Amazonbot generated more observable activity than any other AI-related crawler.
That distinction is important.
What Can We Learn From AI Bot Behaviour?
The most interesting insight isn’t how many requests a bot makes.
The interesting question is:
Which pages are they visiting?
Because every request includes:
- URL visited
- Date and time
- IP address
- User agent
- Frequency of visits
Patterns quickly emerge.
Some pages receive repeated visits.
Others receive a single crawl and are never revisited.
Some content categories appear to attract significantly more AI crawler activity than others.
Repeated Crawling May Indicate
- Content refresh monitoring
- Search indexing updates
- Knowledge graph updates
- Retrieval system checks
- Ranking evaluations
- Content quality reviews
What it does NOT automatically prove is:
- Citation
- AI training usage
- Content inclusion in an AI model
Those conclusions require additional evidence.
However, repeated crawler visits do demonstrate ongoing interest in a page.
Human Visitors vs Bots
One of the biggest misconceptions in website analytics is the belief that every recorded request equals a visitor.
This dataset demonstrates why that assumption is dangerous.
Many requests were generated by:
- Search engines
- AI crawlers
- Monitoring systems
- Vulnerability scanners
- Spam bots
Without server-side tracking, much of this activity remains invisible.
Without JavaScript beacon tracking, many analytics systems struggle to separate genuine visitors from automated traffic.
The result is inflated traffic statistics that often tell only part of the story.
Why I Built My Own Traffic Intelligence Platform
The data used in this article comes from my own Traffic Intelligence platform.
Unlike traditional analytics systems, the platform combines:
Server-Side Tracking
Capturing:
- Bots
- AI crawlers
- HTTP headers
- Status codes
- Security events
- IP intelligence
JavaScript Beacon Tracking
Capturing:
- Human page views
- Sessions
- User journeys
- Real visitor engagement
The combination allows activity to be analysed from both perspectives.
Learn More
Traffic Intelligence Platform:
https://laughingprofessor.net/user-tracking/
Subscription Details:
https://laughingprofessor.net/website-developer/traffic-intelligence
Security Insights From Real Traffic
Tracking visitor behaviour also reveals patterns that standard analytics ignore.
Examples identified during the monitoring period included:
- Fake account registrations
- Email spam activity
- Root file probing
- WordPress login probing
- Automated scraping attempts
Rather than automatically blocking visitors, activity is logged and reviewed before action is taken.
This creates a historical intelligence database rather than a simple firewall log.
What Happens Next?
The AI landscape is changing rapidly.
The most valuable information may not be how many AI bots exist.
It may be understanding:
- Which bots visit your website
- Which content they repeatedly request
- How often they return
- Which pages attract the most attention
- How AI traffic changes over time
As more data is collected, future reports will compare crawler behaviour month-by-month to identify emerging trends.
Final Thoughts
The conversation around AI crawlers is often driven by assumptions.
The numbers above come from a single website with over 1.4 million tracked events collected over 277 days.
What they show is simple:
AI bots are active.
Bot traffic remains substantial.
Human visitors represent only part of the overall activity occurring on a modern website.
And if you’re only looking at page views, you’re probably missing most of the story.
Data source: First-party tracking data collected from LaughingProfessor.net using the Traffic Intelligence Platform. Statistics reflect the tracking period shown and will continue to evolve as additional data is collected.
Leave a Comment