
What 1.4 Million Tracked Events Really Mean: The Story Behind the Numbers
Published by The Laughing Professor
The Numbers Were Never the Point
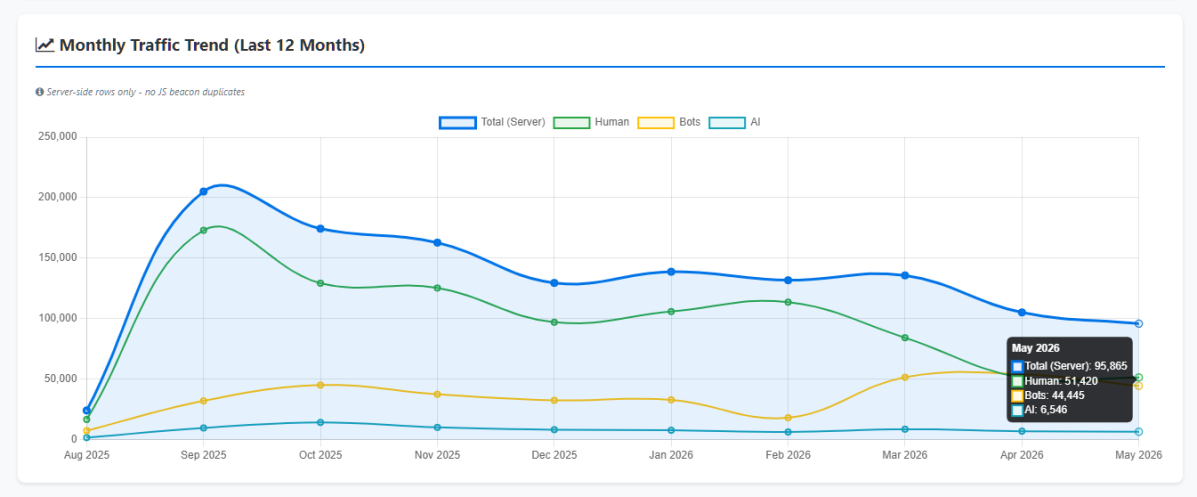
The previous article published the headline figures from 277 days of Traffic Intelligence data collected on LaughingProfessor.net.
Numbers like:
- 1,423,640 tracked events
- 1,299,330 server requests
- 117,263 unique IP addresses
- 79,845 AI crawler requests
- 354,416 bot requests
- 27,441 JS-confirmed human page views
Those numbers raised a question that the original article only began to answer.
What does it all actually mean?
This article goes deeper.
What 117,263 Unique IPs Really Means
Most website owners running a niche site assume they attract traffic from a few thousand visitors.
That assumption is understandable.
If your Google Analytics shows 500 sessions a week, it feels like 500 people found your website.
But the IP data tells a very different story.
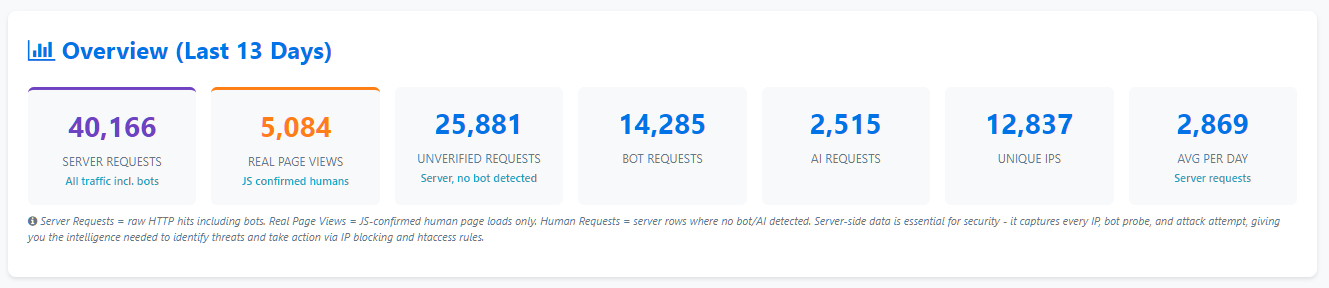
Over 277 days, LaughingProfessor.net recorded 117,263 unique IP addresses.
That is not 117,263 human visitors.
It is 117,263 distinct addresses — representing search engines, AI crawlers, monitoring systems, vulnerability scanners, scrapers, bots, and yes, some genuine human visitors.
This distinction matters enormously.
Every day, regardless of your niche, your website is being accessed by automated systems you never see in standard analytics. They read your content, check your status codes, probe your file structure, index your pages, and sometimes return repeatedly over weeks.
Understanding who — or what — is making those requests is not optional.
It is the entire point of tracking.
How This Data Was Collected
The statistics in both this article and the original are collected using the Traffic Intelligence Platform running on LaughingProfessor.net.
The platform combines two independent tracking methods:
Server-Side Tracking
Every HTTP request hitting the server is captured and logged, including:
- IP addresses
- User agents
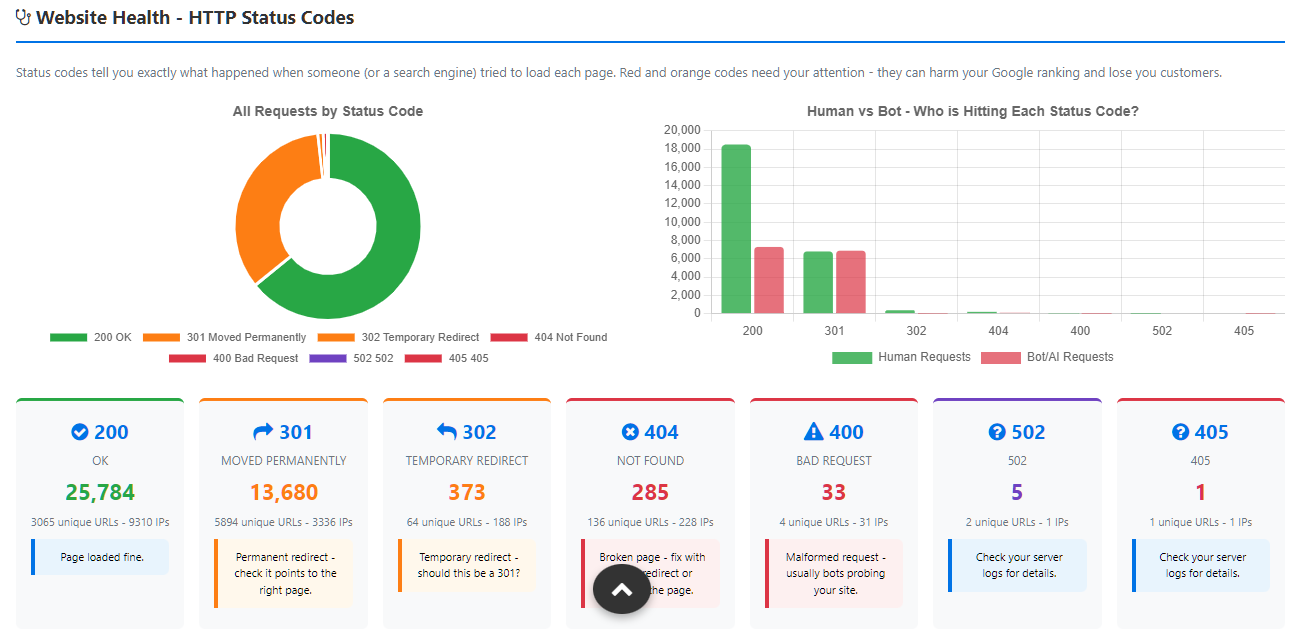
- HTTP status codes (200, 4XX, 5XX)
- Bot signatures
- AI crawler identifiers
- Security events and probing attempts
This layer captures everything — humans, bots, crawlers, and scanners — regardless of whether JavaScript runs.
JavaScript Beacon Tracking
A lightweight beacon fires when a real browser loads a page and executes JavaScript, capturing:
- Human page views
- Session data
- Page titles
- Visitor journeys through the site
This layer filters for genuine human engagement.
The combination of both layers is what makes the data meaningful.
Without server-side tracking, you miss the bots entirely.
Without JavaScript beacon tracking, you cannot separate human visits from automated requests.
Most analytics platforms only give you one layer.
Traffic Intelligence gives you both.
The AI Crawler Data in Detail
This is the dataset that deserves the most attention.
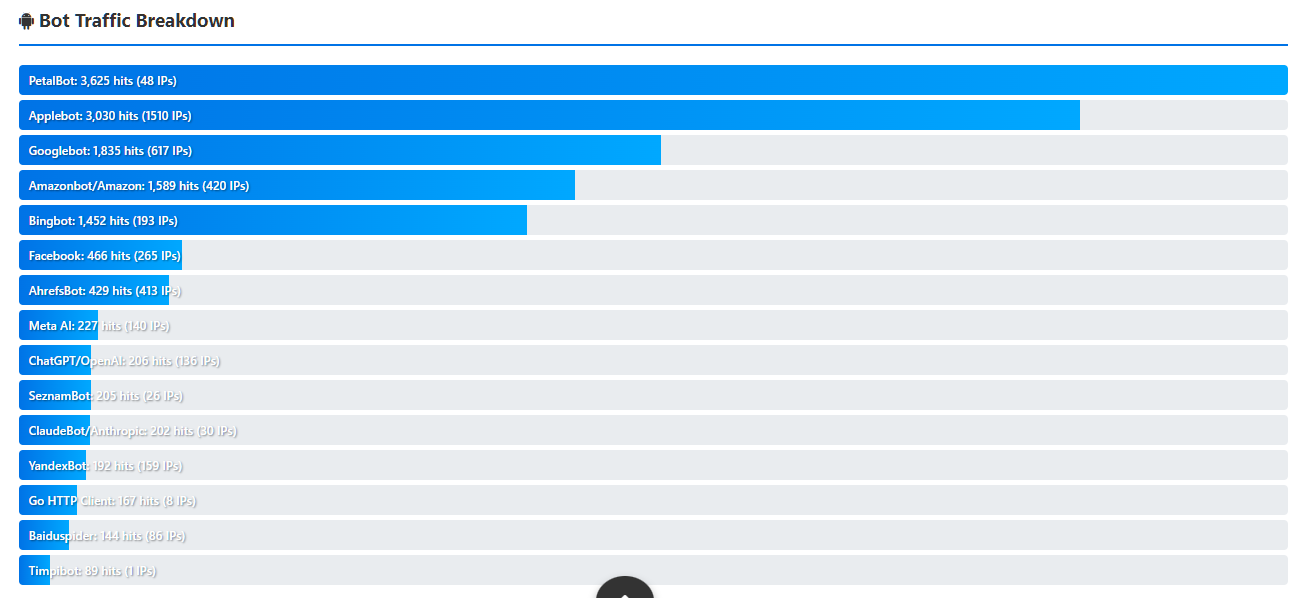
Over 277 days, the following AI-related crawlers were identified through server-side tracking:
| AI Crawler | Requests | Unique IPs |
|---|---|---|
| Amazonbot | 1,503 | 414 |
| ChatGPT | 234 | 155 |
| Meta AI | 223 | 137 |
| ClaudeBot | 210 | 31 |
| Timpibot | 89 | 1 |
| CommonCrawl | 85 | 3 |
| OpenAI | 42 | 10 |
| PerplexityBot | 22 | 7 |
| Bytespider | 5 | 3 |
| YouBot | 5 | 2 |
| GPTBot | 5 | 1 |
| Perplexity | 3 | 3 |
| MistralBot | 1 | 1 |
| Google-Extended | 1 | 1 |
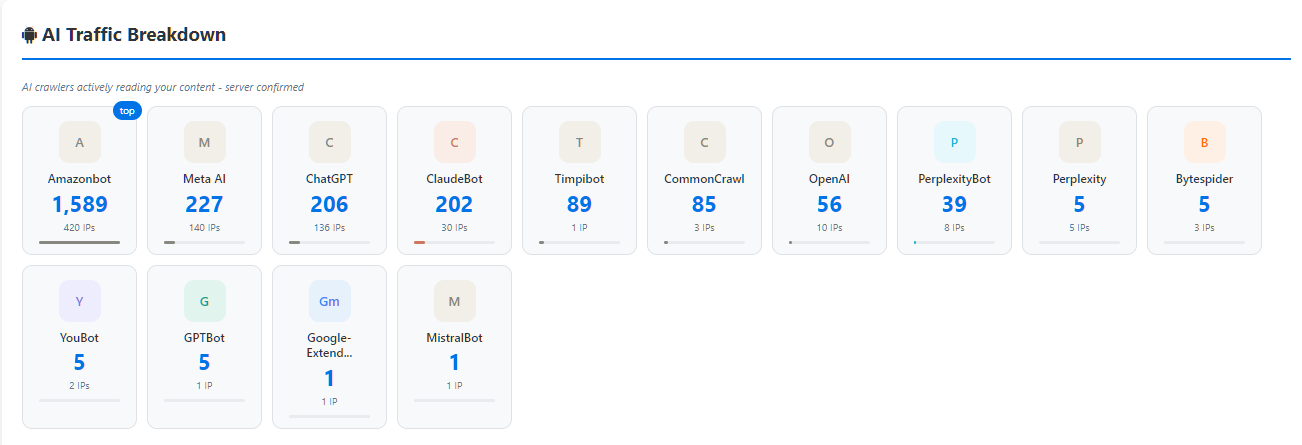
AI crawler activity detected by the Laughing Professor Traffic Intelligence platform.
Several things stand out immediately.
Amazonbot dominates by a significant margin.
Most conversations about AI crawlers focus on OpenAI, ChatGPT, and Google. Yet on this website, Amazonbot generated more than six times the requests of the next closest AI crawler.
The reason is not entirely clear. Amazonbot operates across multiple Amazon services — Alexa, AWS, Audible, and others. Its activity does not necessarily indicate one single use case.
But the volume is real, and it is observed consistently.
ChatGPT and Meta AI are operating at similar levels.
234 requests from ChatGPT versus 223 from Meta AI. These are not dramatically different numbers.
What is interesting is the unique IP counts. ChatGPT used 155 unique IPs for 234 requests. Meta AI used 137 unique IPs for 223 requests.
That means both crawlers are operating from distributed infrastructure rather than a small fixed pool of addresses.
ClaudeBot made 210 requests from only 31 unique IPs.
This is a notably different pattern. Fewer IPs, similar request volume — suggesting more concentrated crawling activity from a smaller address range.
OpenAI and GPTBot appear separately in the data.
This is worth noting. OpenAI infrastructure can present under different user agent strings depending on the service being used. Both are counted here, which shows the value of granular user agent tracking rather than simple keyword matching.
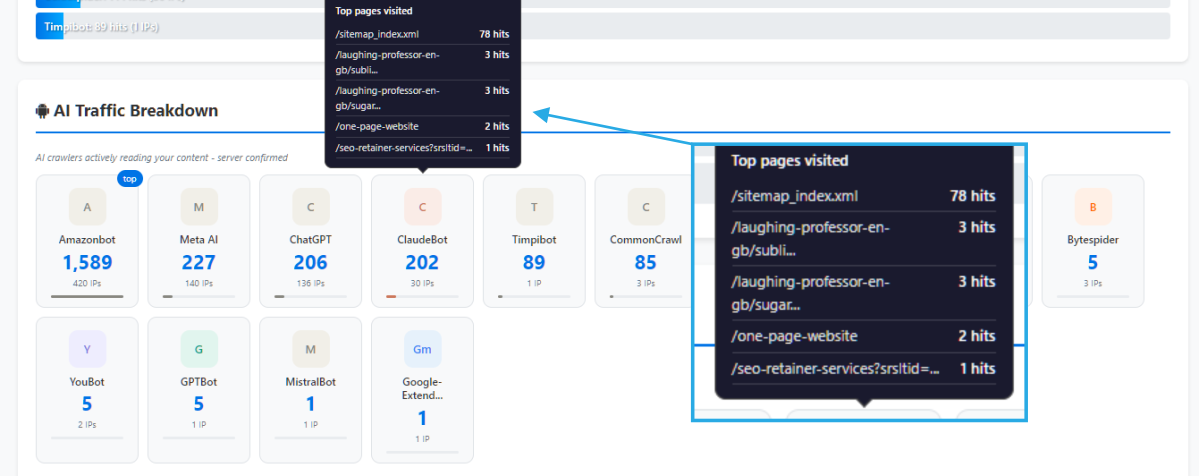
Which Pages Do AI Bots Actually Read?
Tracking that an AI bot visited your website is useful.
Tracking which pages it visited — and how often — is far more useful.
Every request logged by Traffic Intelligence includes:
- The exact URL requested
- Date and timestamp
- IP address
- User agent string
- Frequency of return visits
Patterns emerge quickly when you start reviewing this data over weeks and months.
Some pages receive a single crawl and are never revisited.
Others are repeatedly requested — sometimes weekly, sometimes more frequently — suggesting the crawler is monitoring for updates or repeatedly extracting content.
Some content categories attract significantly more AI crawler attention than others.
What Repeated Crawling May Indicate
When an AI crawler returns to the same page multiple times over an extended period, it can suggest:
- The content is being monitored for changes
- The page has been identified as a useful source
- The page ranks well and is being re-evaluated alongside competing results
- The content falls within a topic area being actively indexed for retrieval systems
What repeated visits do not automatically prove:
- That your content is being used to train an AI model
- That your content will be cited by an AI assistant
- That your website will gain any direct benefit
Those conclusions require additional evidence.
However, repeated attention is not meaningless.
It tells you something about how your content is perceived by automated systems — which increasingly influence how information reaches human readers.
The Human Visitor Reality Check
Here is the number that changes how website owners should think about their traffic.
Over 277 days and 1,299,330 server requests, only 27,441 page views were confirmed through JavaScript beacon tracking.
That is approximately 2.1% of all server requests representing confirmed human engagement.
This does not mean the website failed to attract visitors.
It means that the overwhelming majority of server activity was automated.
This is not unusual.
It reflects the reality of how the modern internet operates.
Every website — regardless of size, niche, or authority — is accessed daily by systems that have nothing to do with human readership.
Search engine spiders crawl constantly.
AI systems ingest content at scale.
Security scanners probe file structures.
Monitoring bots check uptime and response times.
Scrapers harvest data for commercial use.
If you are only looking at page views, you are missing the majority of what is actually happening on your website.
Security Observations From the Same Dataset
Traffic Intelligence is not only useful for understanding visitors and bots.
It also surfaces security-relevant activity that traditional analytics completely ignores.
During the 277-day monitoring period, the platform identified repeated patterns including:
- Fake account registration attempts
- Email abuse originating from the platform
- Root directory probing (attempts to access system-level files)
- WordPress login probing (despite the site not running WordPress)
- Automated scraping attempts across multiple pages
The approach taken here is deliberate.
Rather than automatically blocking every suspicious IP, activity is logged and reviewed. This builds a historical intelligence database — a record of who did what, when, and how often.
Automatic blocking is reactive.
Logged intelligence is strategic.
What the Next Update Will Include
As data collection continues, future reports will expand on several areas:
Month-by-month crawler comparison. Are the same AI crawlers returning? Are new ones appearing? Is request volume growing or declining?
Page-level AI crawler activity. Which specific URLs attract the most repeated AI crawler visits, and what those pages have in common.
Bot behavior patterns. Which bots operate on predictable schedules, and which appear irregularly.
Security trend analysis. Whether probing attempts follow patterns tied to news events, vulnerability disclosures, or other external factors.
The value of this platform is not in any single snapshot.
It is in the accumulation of data over time — and the patterns that only become visible when you have enough of it.
Related Reading
- Which AI Bots Are Really Crawling Websites in 2026? Real Data From 1.4 Million Tracked Events
- Traffic Intelligence Platform Overview
- Traffic Intelligence Subscription Details
- AI Bot SEO Checker
- Which AI Bots Are Crawling Websites in 2026 — Broader Research
Final Thought
The original article stated something that holds up under scrutiny.
Most articles about AI bots are written based on assumptions.
This one — and its follow-up — is written based on data collected from a real website over real time.
The modern internet is no longer a human-only environment.
If your analytics only shows you page views, you are looking at one small corner of what is actually happening.
Data source: First-party tracking data collected from LaughingProfessor.net using the Traffic Intelligence Platform. Statistics reflect the 277-day tracking period referenced in the original article and will continue to evolve as additional data is collected.
Related Products




Leave a Comment